
Knowledge Vortex: When AI Eats Academia
Elsevier, Meta and the fight over who owns knowledge.

There are moments when a lawsuit is more than a lawsuit. It becomes a map of the system underneath. The proposed class action filed on 5 May 2026 by Elsevier, Cengage, Hachette, Macmillan, McGraw Hill and author Scott Turow against Meta and Mark Zuckerberg is one of those moments. On the surface, it is another copyright case in the rapidly expanding legal war over AI training data. But beneath the legal filing sits something much bigger: a fight over whether scholarly knowledge, educational publishing and literary labour can be absorbed into commercial AI systems as if they were simply free raw material lying around on the digital ground. It is a cracker of a case because almost nobody enters it with clean hands, yet almost everyone has something at stake.

The complaint, filed in the Southern District of New York, accuses Meta and Zuckerberg of unauthorised reproduction and distribution of copyrighted works used to source, develop and train Meta’s Llama AI models. The six counts include reproduction by torrenting, reproduction via web scrapes, reproduction during training, distribution by torrenting, contributory infringement against Zuckerberg personally, and removal or alteration of copyright management information under the DMCA. The complaint alleges that Meta torrented millions of copyrighted books and journal articles from pirate sites, downloaded unauthorised web scrapes of large parts of the internet, and then copied those works repeatedly to train Llama. It describes this as “one of the most massive infringements of copyrighted materials in history.” Reuters and AP have also reported the case as a major new front in the AI copyright wars, with publishers alleging that Meta used copyrighted material ranging from textbooks and scientific articles to novels to train Llama.
The lawsuit does not whisper. It claims that Meta reproduced and distributed millions of works without permission, compensation or attribution, and that Zuckerberg personally authorised or encouraged the conduct. It also alleges that Meta stripped copyright management information from works it used, partly to conceal training sources and facilitate unauthorised use. The complaint’s framing is deliberately muscular: Meta, it argues, did not merely “learn” from culture; it copied, processed, stripped, stored, trained on and commercialised protected works at industrial scale.
The uncomfortable twist is that Elsevier is not usually cast as the heroic defender of academic labour. For decades, scholars have criticised the large academic publishers for turning publicly funded research, unpaid peer review, university prestige and authorial ambition into subscription products. Elsevier, in particular, has often symbolised the enclosure of scholarly knowledge behind paywalls. Many academics have spent years arguing that the current publishing system extracts value from scholars while offering limited compensation, limited openness and limited control. So there is real irony in seeing Elsevier present itself as a defender of authors and scholarly rights against Big Tech.
But the irony does not make the case trivial. It makes it more interesting. The Meta case forces a harder question: what happens when the old enclosure of knowledge, the paywall, is joined by a new enclosure, the model wall? The paywall restricted access to articles, books and databases. The model wall absorbs those materials into proprietary AI systems, transforms them into statistical representations, and then monetises the outputs through chatbots, APIs, enterprise tools, educational products and productivity platforms. In the old system, users paid to read the article. In the new system, they may pay to query a model trained on the article without ever encountering the author, the citation, the argument, the journal, the method, or the institutional context from which the knowledge came.

That is why some academics may find themselves in the strange position of hoping Elsevier does not lose too badly. Times Higher Education captured this tension neatly, reporting warnings from experts that a broad Meta victory could amount to “open season” on scholars’ rights to control how their work is used and represented. The issue is not that academics suddenly love Elsevier’s business model. It is that a world in which Meta, OpenAI, Anthropic and other AI companies can ingest scholarly work without permission, attribution or compensation may not be an improvement on the paywalled world. It may simply replace one form of extraction with another, larger and less accountable one.
The Authors Alliance piece on the case adds an important complication. It notes that the proposed class is not limited to trade authors or textbook publishers. It potentially covers legal or beneficial owners of registered copyrights in books with ISBNs and journal articles with DOIs or ISSNs that Meta allegedly reproduced through torrenting, scraping or training. That means academic journal articles are directly in the frame, including works where authors retained rights, jointly owned rights, or assigned core rights to publishers. In many commercial journal arrangements, the author may retain certain reuse or repository rights, but the core exclusive rights at issue in this lawsuit may sit with the publisher rather than the author. In those cases, the publisher, not the scholar, is the class member with legal standing.
This is where the moral geometry becomes properly awkward. Elsevier may be suing over uses of scholarship that many authors care about, but some of those same authors may have little direct say because they transferred copyright in the first place. Authors Alliance points out that an author who deliberately preserved public access to their work through a repository policy may still lack standing to opt out of litigation pursued in the publisher’s name. That means the case is not simply “publishers defending authors.” It is also a reminder that academic authors often lose legal control over their own work long before AI companies arrive to absorb it.
The open access wrinkle is even more interesting. Many fully and hybrid open access articles are published under Creative Commons licences, often CC BY, which allow copying, distribution and reuse under certain conditions, usually including attribution. Whether those licences authorise copying entire articles into commercial AI training corpora, especially where copyright management information is allegedly stripped, remains unresolved. Authors Alliance suggests that if the court has to decide which Creative Commons-licensed works are inside or outside the proposed class, this case could become a vehicle for clarifying whether and how open licences apply to AI training. That would have implications far beyond Meta and Llama.
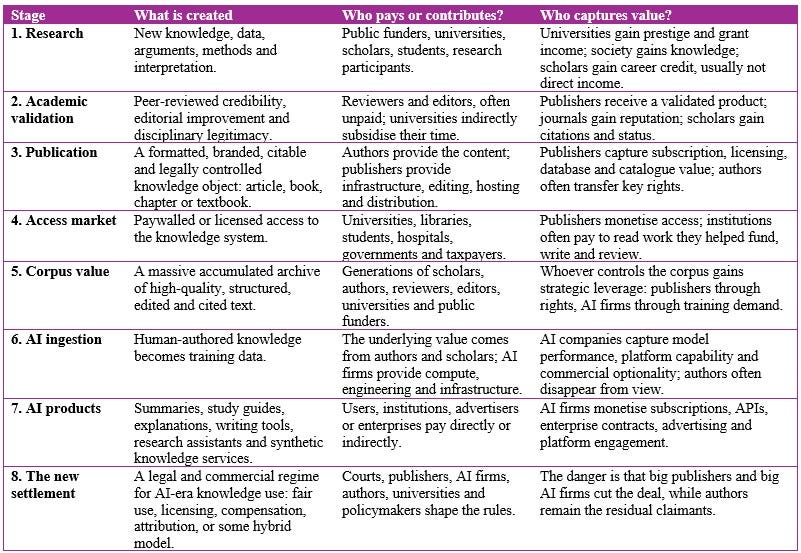
This is the deeper political economy of the case. Scholars write the papers. Reviewers assess them for free. Universities provide salaries, libraries, infrastructure and reputational scaffolding. Public funders often finance the research. Publishers organise, package, distribute and monetise the outputs. Now AI companies want to ingest the accumulated corpus, abstract its value and sell access to machine-generated knowledge services built partly on that foundation. The scholar is still the origin point of the knowledge system, but not necessarily the economic beneficiary. The danger is that academic work becomes training infrastructure: essential, invisible and undercompensated. Put differently, the AI copyright fight is not just about whether a model copied a text. It is about how value moves through the knowledge system—from public funding and unpaid academic labour to publishing platforms, licensing markets and now AI products.
Meta’s likely defence is familiar. AI companies generally argue that training large language models on copyrighted material can be fair use because the model does not simply reproduce original works but learns patterns from them. The output, they argue, is transformative. It is not a pirated ebook or a copied journal article; it is a probabilistic system capable of generating new text. Meta has indicated that it will fight the lawsuit, as it argues that AI training can fall under fair use.
The publishers’ counterargument is that “learning” is not magic. Before a model can learn from a book or article, the work has to be copied, stored, processed and transformed into training data. If the input corpus includes pirated or paywalled material, then the fairness of the use becomes much harder to defend politically, even if the legal test remains contested. The complaint argues that Meta used sources such as LibGen, Anna’s Archive, Sci-Hub, Sci-Mag and other alleged pirate repositories, and that torrenting is not merely downloading but also distribution through peer-to-peer file sharing.
The complaint also pushes a market-harm theory. It argues that Llama can generate substitutes for copyrighted works: verbatim and near-verbatim passages, summaries, paraphrases, study guides, knockoffs, imitations, derivative works and AI-generated content that floods markets already occupied by human authors. The complaint describes Llama as, in effect, an “infinite substitution machine,” able to produce competing text at speed and scale. It gives examples involving textbooks, scholarly articles, travel guides and fiction, including claims that Llama can produce misleading or hallucinated summaries of academic articles that nevertheless appear authoritative.
This reputational dimension matters. If an AI system produces an incorrect summary of a paper, hallucinates a claim, strips away context, or blends one scholar’s argument with another’s, who bears the damage? The model provider may disclaim responsibility. The publisher may assert copyright. The university may see reputational effects. The author may be misrepresented. The reader may never know the difference. For scholars, rights are not only about payment. They are also about attribution, integrity, context and control over how knowledge is represented.
None of this requires pretending that Elsevier is the uncomplicated good guy. But neither does it require pretending that Meta is simply advancing open knowledge. AI companies often speak the language of access, innovation and democratisation, but they are building highly capitalised, proprietary systems whose economic value depends on absorbing vast amounts of human-produced content. When that content includes academic work, the moral question becomes sharp: is this democratisation of knowledge, or a new extractive layer sitting above the knowledge system?
The better position is probably not to side with Elsevier as a corporation, nor with Meta as a platform, but with authors, scholars and the wider public interest in a sustainable knowledge system. Authors should not be erased from the value chain. Scholars should not have their work absorbed into commercial systems without meaningful say. Students and readers should not be trapped between unaffordable paywalls and unaccountable model outputs. Publishers should not be allowed to use this moment simply to entrench old oligopolies. AI companies should not be allowed to convert the world’s intellectual labour into private infrastructure while calling the process inevitable.
The real policy problem is that the current system has no adequate settlement for AI-era knowledge use. Licensing everything through large publishers may consolidate the power of incumbents and make AI more expensive, slower and more centralised. Allowing unrestricted ingestion may strip authors and scholars of control, weaken knowledge institutions and reward whoever has the compute capacity to absorb the most material fastest. A better settlement would need to distinguish between lawful access and piracy, commercial and non-commercial use, scholarly and entertainment content, attribution and anonymity, model training and output substitution, public interest research and private platform enclosure.
This is why the case matters beyond Meta and Elsevier. If Meta wins broadly, the precedent may strengthen the claim that AI companies can absorb copyrighted knowledge at scale under fair use, even where the resulting systems compete with or substitute for existing knowledge markets. If the publishers win broadly, the AI economy may become more licensing-dependent, more expensive and more tightly controlled by those who already own large catalogues of rights. Neither outcome is pure. Both contain risks. But the worst outcome would be one in which the authors, scholars and educators whose labour makes the system valuable are treated as background noise.
The paywall was the defining enclosure of the old academic economy. The model wall may become the defining enclosure of the next one. Elsevier v Meta is messy, compromised, ironic and strategically enormous. That is exactly why it is worth watching. It asks whether AI will be built through consent, licensing, attribution and accountable knowledge governance, or whether the digital record of human thought will be treated as an unpriced resource base for the next generation of platform power.
For once, the interesting question is not whether Elsevier is right or Meta is wrong. The question is whether the people who produce knowledge will have any real say in the systems now being built from it.